Motivation and Project Context
This Master’s project explores how reinforcement learning (RL) can enable robots to autonomously build stable structures, without the use of scaffolds or human intervention. It focuses on the design of reward functions that guide the learning process of robots as they place building blocks to form spanning structures connecting two fixed points. The broader vision is to contribute to the field of autonomous construction by leveraging the ability of RL to adapt and improve through interaction with its environment.
The construction problem is framed as a sequential decision-making task, where a robot places one block at a time following a policy it learns through trial and error. The environment simulates the physical constraints of the construction site and evaluates the resulting structure at each step. The robot learns to act through a Soft Actor-Critic (SAC) algorithm, a technique in reinforcement learning that encourages both goal-directed behavior and exploration by maximizing entropy.

Example of stable structure built by the agent
Structural Stability and Reward Shaping
The stability of a structure is a critical aspect of this project. A mechanical model known as Rigid Block Equilibrium (RBE) is used to check whether a given configuration of blocks can stand on its own. This model assumes that the blocks are rigid and interact through compression, offering a fast way to determine if a structure is stable or not. This information is used not only to evaluate the end result but also to influence how the robot learns throughout the construction process.
A key challenge is to design a reward function that effectively teaches the robot what a “good” structure is. Traditional binary rewards—success or failure—are often too simplistic. They provide little feedback during the intermediate steps of construction and can lead the robot to miss important structural patterns. To address this, the project develops new reward strategies based on metrics that measure how stable a structure is, even before it is complete.
Two stability metrics were explored:
- One based on how much vertical load each block can support before the structure collapses
- Another based on how far a structure can be tilted before it becomes unstable
These metrics help quantify not just whether a structure works, but how robust it is. This richer information is then used to fine-tune the reward function given to the learning agent.
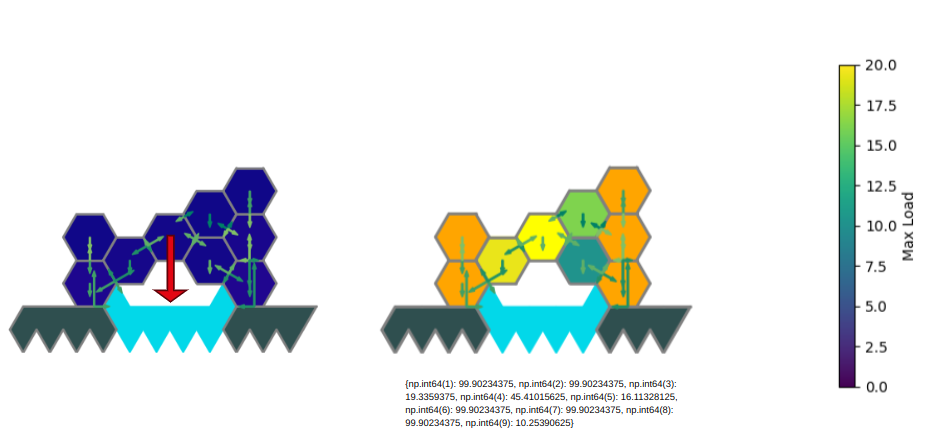
Load bearing metric example result
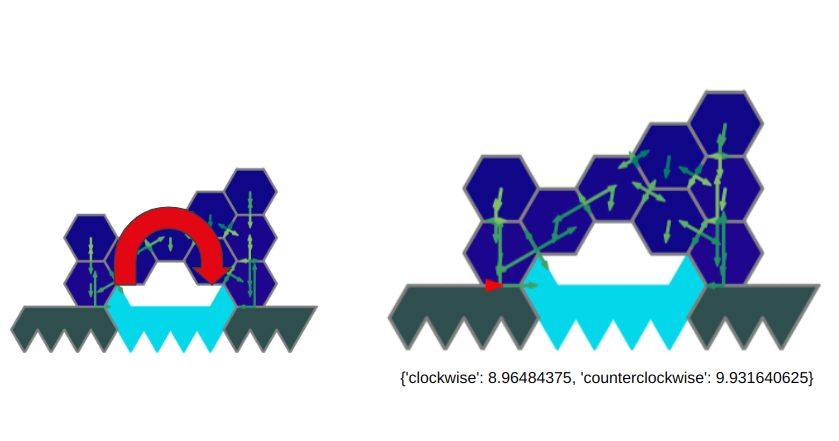
Tilting metric example result
Evaluation and Broader Impact
A database of over 1,000 different structures was generated using search algorithms, enabling comparison of the metrics across various design scenarios. The findings revealed that:
- The two metrics are highly correlated
- The load-bearing metric is computationally simpler and more practical to use
- The load-bearing metric indicates where the weak points in a structure are located

Animation of robot successfully building a spanning structure
By using this kind of reward shaping, the robot not only learns to build structures that remain standing, but also structures that are robust to failure. This improves learning efficiency and leads to better performance in the long run. Instead of rewarding only complete, successful structures, the agent now receives continuous feedback throughout the building process, making it easier to explore new designs and avoid structural weaknesses.
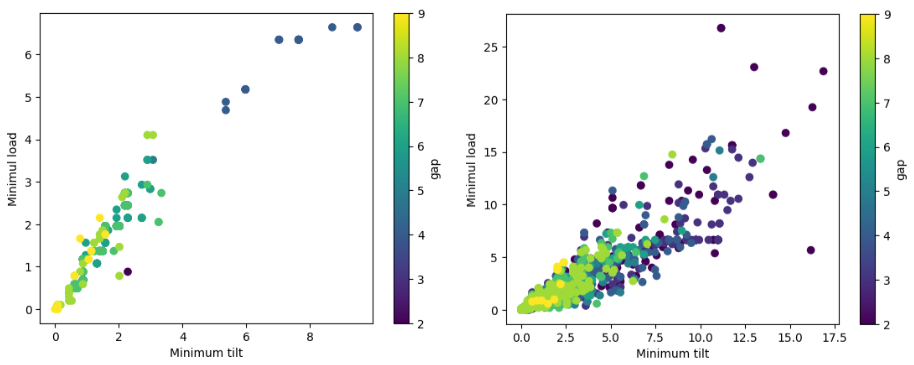
Comparison between tilt and load bearing
Learning Integration and Experimental Evaluation
After validating that the stability metrics correlate well and provide meaningful information, these metrics were directly integrated into the reinforcement learning pipeline. They were used to shape the reward signals that guided the agent during training. Instead of using a binary notion of success and failure, the agent was rewarded proportionally based on the robustness of each intermediate structure it built.
Experiments were conducted to compare the behavior and performance of agents trained with the shaped rewards against those trained with a simple baseline. This comparison demonstrated that the use of structural stability metrics in the reward design led to more resilient constructions. This approach enabled to develop a more refined understanding of what makes a structure stable, improving the performance throughout the construction process.
Types of Reward Implemented
The image below shows the tilt and load bearing achieved by agents trained with different types of reward functions. These reward types are:
- binary: The agent receives a reward of 1 if the final structure is stable, and -1 if it is not. No reward is given during construction steps.
- stability: Similar to binary, but if the final structure is stable, the reward is proportional to the stability of the structure (not just 1 or -1).
- pos: During construction, the agent receives small positive rewards for steps where the load bearing is high.
- neg: During construction, the agent receives small negative rewards for steps where the load bearing is low.
- posneg: The agent receives both small positive rewards for high load bearing steps and small negative rewards for low load bearing steps during construction.
The reward types can be combined, for example:
- binary_pos: Binary reward at the end, plus small positive rewards during construction.
- stability_neg: Stability-based reward at the end, plus small negative rewards during construction.
- stability_posneg: Stability-based reward at the end, plus both small positive and negative rewards during construction.
Summary:
- “binary” and “stability” are for the final structure only.
- “_pos”, “_neg”, and “_posneg” add extra feedback during the building process.
- Combining these strategies helps the agent learn to build more stable and robust structures.
This helps to compare how different reward strategies affect the quality of the structures built by the agent. In this next image, we present some of the results of the stability quality using the metrics developed, for each type of reward used.
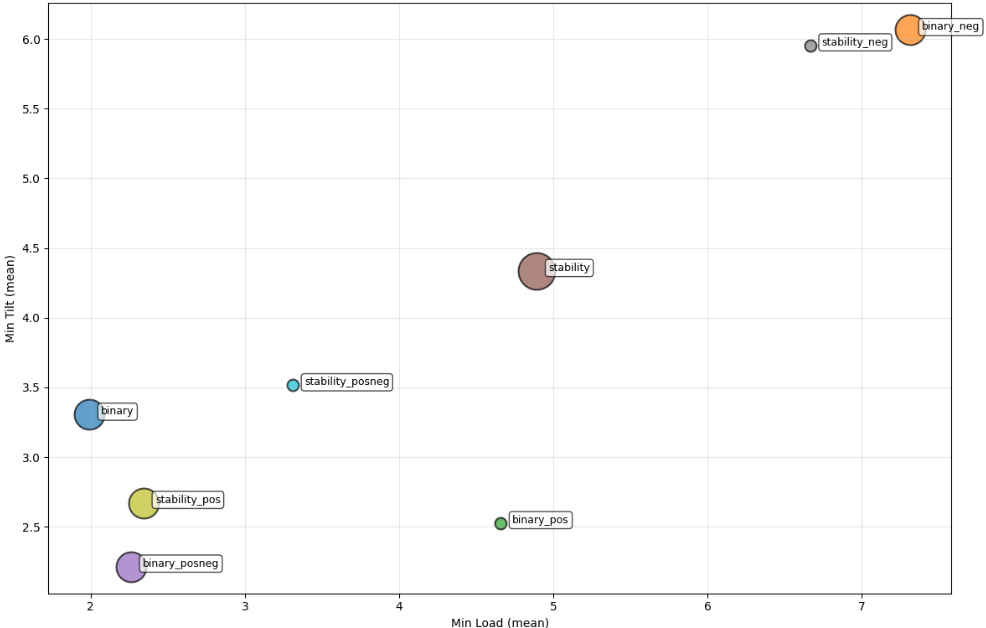
Comparison of load bearing capacity and tilting capacity between different reward strategies
Each reward shapping method gave some imporvement on the results when comparing with the baseline binary type.
This project is part of a broader effort to understand how machine learning and robotics can merge with architectural and structural design to produce autonomous systems capable of creative and efficient construction.